
Stack
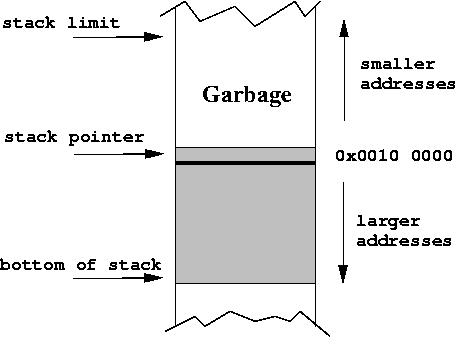
When a program starts executing, a certain contiguous section of memory is set aside for the program called the stack.
.
Here's a diagram of a push operation.

Here's a diagram of the pop operation.
Stacks and Functions
Let's now see how the stack is used to implement functions. For each function call, there's a section of the stack reserved for the function. This is usually called a stack frame.
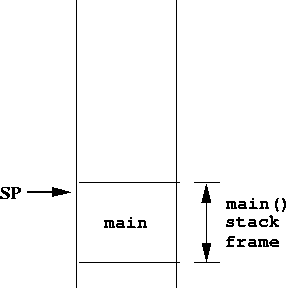
Let's imagine we're starting in main() in a C program. The stack looks something like this:

We'll call this the stack frame for main(). It is also called the activation record. A stack frame exists whenever a function has started, but yet to complete.
Suppose, inside of body of main() there's a call to foo(). Suppose foo() takes two arguments. One way to pass the arguments to foo() is through the stack. Thus, there needs to be assembly language code in main() to "push" arguments for foo() onto the the stack. The result looks like:

As you can see, by placing the arguments on the stack, the stack frame for main() has increased in size. We also reserved some space for the return value. The return value is computed by foo(), so it will be filled out once foo() is done.
Once we get into code for foo (), the function foo() may need local variables, so foo() needs to push
some space on the stack, which looks like:
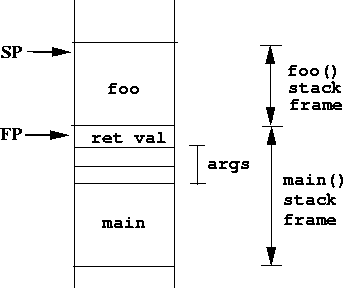
foo() can access the arguments passed to it from main() because the code in main() places the arguments just as foo() expects it.
We've added a new pointer called FP which stands for frame pointer. The frame pointer points to the location where the stack pointer was, just before foo() moved the stack pointer for foo()'s own local variables.
Having a frame pointer is convenient when a function is likely to move the stack pointer several times throughout the course of running the function. The idea is to keep the frame pointer fixed for the duration of foo()'s stack frame. The stack pointer, in the meanwhile, can change values.
Thus, we can use the frame pointer to compute the locations in memory for both arguments as well as local variables. Since it doesn't move, the computations for those locations should be some fixed offset from the frame pointer.
And, once it's time to exit foo(), you just have to set the stack pointer to where the frame pointer is, which effectively pops off foo()'s stack frame. It's quite handy to have a frame pointer.
We can imagine the stack growing if foo() calls another function, say, bar(). foo() would push arguments on the stack just as main() pushed arguments on the stack for foo().
So when we exit foo() the stack looks just as it did before we pushed on foo()'s stack frame, except this time the return value has been filled in
.
Once main() has the return value, it can pop that and the arguments to foo() off the stack.
Recursive Functions
Surprisingly enough, there's very little to say about recursive functions, because it behaves just as non-recursive functions do. To call a recursive function, push arguments and a return value on the stack, and call it like any other function.
It returns back the same way as well.
How MIPS Does It
In the previous discussion of function calls, we said that arguments are pushed on the stack and space for the return value is also pushed.
This is how CPUs used to do it. With the RISC revolution (admittedly, nearly 20 years old now) and large numbers of registers used in typical RISC machines, the goal is to (try and) avoid using the stack.
Why? The stack is in physical memory, which is RAM. Compared to accessing registers, accessing memory is much slower---probably on the order of 100 to 500 times as slow to access RAM than to access a register.
MIPS has many registers, so it does the following:
- There are four registers used to pass arguments: $a0, $a1, $a2, $a3.
- If a function has more than four arguments, or if any of the arguments is a large structure that's passed by value, then the stack is used.
- There must be a set procedure for passing arguments that's known to everyone based on the types of the functions. That way, the caller of the function knows how to pass the arguments, and the function being called knows how to access them. Clearly, if this protocol is not established and followed, the function being called would not get its arguments properly, and would likely compute bogus values or, worse, crash.
- The return value is placed in registers $v0, and if necessary, in $v1.
In general, this makes calling functions a little easier. In particular, the calling function usually does not need to place anything on the stack for the function being called.
However, this is clearly not a panacea. In particular, imagine main() calls foo(). Arguments are passed using $a0 and $a1, say.
What happens when foo() calls bar()? If foo() has to pass arguments too, then by convention, it's supposed to pass them using $a0 and $a1, etc. What if foo() needs the argument values from main() afterwards?
To prevent its own arguments from getting overwritten, foo() needs to save the arguments to the stack.Thus, we don't entirely avoid using the stack.
Leaf Procedures
In general, using registers to pass arguments and for return values doesn't prevent the use of the stack. Thus, it almost seems like we postpone the inevitable use of the stack. Why bother using registers for return values and arguments?
Eventually, we have to run code from a leaf procedure. This is a function that does not make any calls to any other functions. Clearly, if there were no leaf procedures, we wouldn't exit the program, at least, not in the usual way. (If this isn't obvious to you, try to think about why there must be leaf procedures).
In a leaf procedure, there are no calls to other functions, so there's no need to save arguments on the stack. There's also no need to save return values on the stack. You just use the argument values from the registers, and place the return value in the return value registers.






